Filter by
The language used throughout the course, in both instruction and assessments.
Build job-relevant skills in under 2 hours with hands-on tutorials.
Learn from top instructors with graded assignments, videos, and discussion forums.
Learn a new tool or skill in an interactive, hands-on environment.
Get in-depth knowledge of a subject by completing a series of courses and projects.
Earn career credentials from industry leaders that demonstrate your expertise.
Earn your Bachelor’s or Master’s degree online for a fraction of the cost of in-person learning.
Graduate level learning within reach.
3,613 results for "hive"
Coursera Project Network
Skills you'll gain: Data Science, Deep Learning, Machine Learning, Tensorflow

Coursera Project Network
Skills you'll gain: Deep Learning, Python Programming, Tensorflow

Coursera Project Network
Skills you'll gain: Deep Learning, Python Programming

Coursera Project Network
Skills you'll gain: Data Science, Deep Learning, Machine Learning, Python Programming
Searches related to hive
In summary, here are 10 of our most popular hive courses
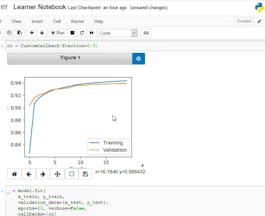
- Creating Custom Callbacks in Keras: Coursera Project Network
- AutoML avec AutoKeras - Classification d'images: Coursera Project Network
- Introducción al Deep Learning: Coursera Project Network
- Image Classification on Autopilot with AWS AutoGluon: Coursera Project Network